- 그룹화-
두개 이상 컬럼 그룹화
deptno를 기준으로 그룹화 하고 그 결과 내에서 job 기준으로 그룹화
select deptno , job from emp group by deptno , job;
select deptno , job , count(*) from emp group by deptno , job;
select deptno , job , count(*) , avg(sal) from emp group by deptno , job;
그룹화한 결과에 조건을 적용
<having>: 그룹화 한 결과에 조건을 적용 하는 문장
위의 결과에서 평균 급여가 2000이상인 결과만 조회
select deptno , job , count(*) , avg(sal)
from emp
group by deptno , job
having avg(sal) >= 2000;
급여가 3000 이하인 사원만 가지고 부서별, 직급별 그룹화를 하고 평균 급여가 2000이상인 결과 조회
select deptno , job , count(*) , avg(sal)
from emp
where sal <= 3000
group by deptno , job
having avg(sal) >= 2000
order by deptno asc;date 타입을 문자로 표현: date_formet()
select date_format(hiredate, '%Y') from emp;<예제1>
연습문제
1. 부서별 평균급여, 최고급여, 최저급여, 사원수 조회(평균급여는 소수점 둘째자리에서 반올림)
select deptno as '부서번호' , round(avg(sal),1) as '평균급여', max(sal)'최고급여' , min(sal)'최저급여' , count(*)'사원수' from emp group by deptno order by deptno;
2. 직급별 사원수 조회(단 3명 이상인 결과만 출력)
select job , count(*) from emp group by job having count(*) >=3;
3. 연도별 입사한 사원수 조회(조회결과 : 연도(yyyy), 사원수)
select date_format(hiredate, '%Y') as '입사년도' , count(*) as '사원수' from emp group by date_format(hiredate, '%Y') having count(*);
3-1. 위의 결과에서 각 연도별로 부서별 입사한 사원수 조회(조회결과 : 연도(yyyy), 부서번호, 사원수)
select date_format(hiredate, '%Y') as '입사년도' , deptno as '부서 번호', count(*) as '사원수' from emp group by date_format(hiredate, '%Y') , deptno having count(*);
-join-
두개 이상의 테이블을 하나의 테이블 처럼 사용할때
select * from emp; -- 테이블1
select * from dept; -- 테이블2
select * from emp , dept; -- join
내부 조인(inner join)
조인 하려는 두 테이블에 공통 컬럼이 존제해야함
select *from emp , dept where emp.deptno = dept.deptno;테이블 이름을 줄여서 사용
select * from emp e ,dept d where e.deptno = d.deptno;
<에러>
select empno , ename , job , deptno , dname , loc from emp e ,dept d where e.deptno = d.deptno;이 상황은 deptno 컬럼은 두 테이블에 모두 있기 때문에

ambiguous 에러가 나타난다
그렇기 때문에
select e.empno , e.ename , e.job , e.deptno , d.dname , d.loc from emp e ,dept d where e.deptno = d.deptno;위와 같이 테이블 이름을 줄여서 쓸때에는 어느 테이블에 있는 것인지 찍어주어야한다
emp 테이블 전체 조회
select e.* from emp e , dept d where e.deptno = d.deptno;
<예제2>
emp , dept 를 조인하여 empno , ename , deptno , dname , loc 조회
( 단 급여가 2500 이상인 사원만 조회하고 , 조회 결과는 사원 이름 기준으로 오름차순)
select e.empno , e.ename , e.deptno , d.dname , d.loc from emp e,dept d where e.deptno = d.deptno and e.sal >= 2500 order by e.ename asc;
서브 쿼리(sub qurey)
서브 쿼리는 두 문장을 하나의 문장으로 사용하는것이다
<예문>
-- 최저 급여를 받는 사원의 이름
select * from emp;
-- 1.최저급여가 얼마인지? => 800
select min(sla) from emp;
-- 2. 800 급여를 받는 사원의 이름 => SMITH
select ename from emp where sal = 800;
-- 위의 두 문장을 서브쿼리로
select ename from emp where sal = (select min(sal) from emp);우선 전체 사원목록중 최저 급여는 800 이름은 smith 이다
이중에서 최저 급여가 얼마인지 보자
그럼 3번째 문장인 저 급여를 받는사람의 이름을 확인해보면
이제 저 두문장을 서브쿼리로 한문장으로 만들어준뒤 실행을 하면
위와 똑같은 결과가 나온다
그럼 반대로 최고 급여를 받는 사원의 정보를 조회해보자
select * from emp where sal =(select max(sal) from emp);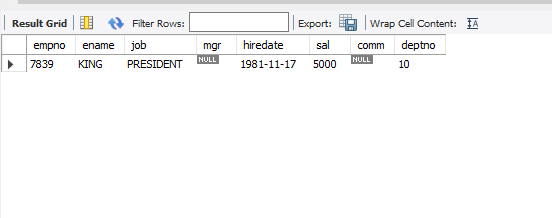
이런식으로 두가지 문장을 한번에 사용할수 있다
<예제3>
1. clark 보다 늦게 입사한 사원 조회
select * from emp where hiredate > (select hiredate from emp where ename = 'clark');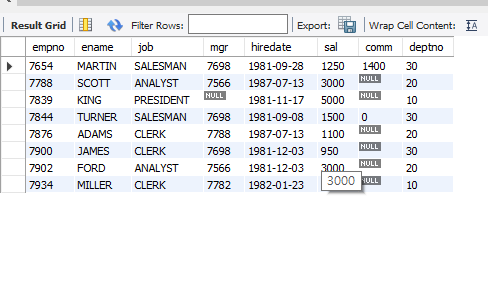
2. 부서번호가 20인 사원 중에서 전체 사원 평균 급여보다 높은 급여를 받는 사원 조회
select * from emp where sal > (select avg(sal) from emp) and deptno = 20;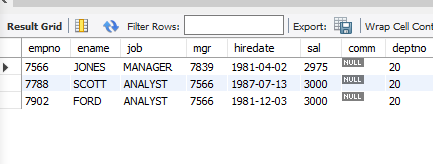
3. 2번 조회 결과에서 부서이름, 부서위치도 함께 조회
select * from emp e , dept d where e.deptno = d.deptno and e.sal > (select avg(sal) from emp) and e.deptno= 20;
4. martin과 같은 부서 사원 중에서 전체 사원 평균 급여보다 높은 급여를 받는 사원 조회
select * from emp where sal > (select avg(sal) from emp) and deptno = (select deptno from emp where ename = 'martin');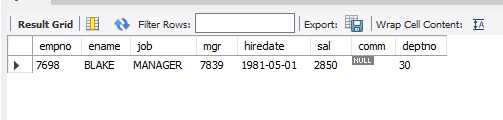
제약 조건(Constraints)
a. 테이블에 데이터를 저장할 때의 규칙을 지정하는것
기본문법
create table [테이블이름] (
[컬럼이름1] [타입] 제약조건 종류 (fk 제외한 나머지 종류가 올 수 있음),
[컬럼이름2] [타입] primary key,
[컬럼이름3] [타입] unique,
[컬럼이름4] [타입] not null,
[컬럼이름5] [타입] unique not null -- 2개를 동시에 주는것도 가능
--fk
constraint [ 제약조건이름(마음대로지정)] foreign key(fk 로 지정할 컬럼 이름)
references [부모테이블 이름] (참조할 컬럼 이름)
);
b. 종류
i.primaty key(pk, 기본키 , 주키)
- 보통 테이블당 하나의 pk를 가짐
- 반드시 값이 입력되어야 하고 같은 값을 입력할 수 없음
drop table if exists member7;
create table member7(
id bigint,
member_email varchar(20) not null unique,
member_password varchar(20) not null,
created_at datetime default now(),
constraint pk_member7 primary key(id)
);
-- 자동 번호 적용하기 (bigint auto_increment 는 pk 컬럼에만 지정가능)
drop table if exists member8;
create table member8(
id bigint auto_increment,
member_email varchar(20) not null unique,
member_password varchar(20) not null,
created_at datetime default now(),
-- id2 bigint auto_increment, -- 일반 컬럼에는 지정 불가
constraint pk_member8 primary key(id)
);
select * from member8;
-- auto_increment를 지정하면 값을 따로 주지않아도 됨
insert into member8(member_email , member_password) value('aa@aa.com', '1234');
insert into member8(member_email , member_password) value('bb@bb.com', '1234');ii. foreign key(fk , 보조키 , 외래키)
- 참조관계를 지정할 때 사용 ( 부모 테이블 , 자식 테이블)
- 자식테이블은 부모테이블의 pk 컬럼을 참조하는 컬럼을 가짐
- 부모 pk 컬럼에 없는 값이 자식 컬럼에 저장되지 않도록 함
iii. not null
- 해당 컬럼에 값을 꼭 입력해야 함
drop table if exists member2;
create table member2(
id bigint not null,
member_email varchar(20),
member_password varchar(20)
);
select* from member2;
insert into member2(id,member_email , member_password) value(1, 'aa@aa.com', '1234');
-- id를 뺀 나머지 값만 입력
insert into member2(member_emali, member_password) value('bb@bb.com' , 1234);
insert into member2(id,member_email , member_password) value(null, 'cc@cc.com', '1234');
insert into member2(id,member_email , member_password) value(4, null, '1234');iv. unique
- 해당 컬럼에 같은 값을 입력 하려고 하면 저장되지 않음
drop table if exists member3;
create table member3(
id bigint not null unique,
member_email varchar(20),
member_password varchar(20)
);
insert into member3(id,member_email , member_password) value(1, 'aa@aa.com', '1234');
insert into member3(id,member_email , member_password) value(1, 'bb@bb.com', '1234');
insert into member3(id,member_email , member_password) value(1, 'bb@bb.com', null);v. default
- 기본으로 입력 되는 값을 지정할 수 있음
drop table if exists member5;
create table member5 (
id bigint not null unique,
member_email varchar(20) not null unique,
member_password varchar(20) not null,
created_at datetime default now()
);
select * from member5;
insert into member5(id, member_email, member_password, created_at)
values(1, 'aa@aa.com', '1234', now());
-- defalut 로 지정한 컬럼은 따로 값을 주지 안하도 값이 default 로 지정한 값ㅇ ㅣ저장됨
insert into member5(id, member_email, member_password)
values(2, 'bb@bb.com', '1234'
);
drop table if exists member6;
create table member6(
id bigint primary key,
member_email varchar(20) not null unique,
member_password varchar(20) not null,
created_at datetime default now()
);
insert into member6(id,member_email , member_password) value(1, 'aa@aa.com', '1234');
insert into member6(id,member_email , member_password) value(2, 'bb@bb.com', '1234');
'개발일지' 카테고리의 다른 글
| 개발일지 -alter ERD- (0) | 2024.01.05 |
|---|---|
| 개발일지 -참조관계 , 수정쿼리- (1) | 2024.01.05 |
| MySQL (1) | 2024.01.02 |
| 개인 프로젝트 (0) | 2023.12.29 |
| 인터페이스 , 예외처리 (0) | 2023.12.29 |


